R语言的基础
条评论1. R 初步
R 语言的入门,文档下载
链接:https://pan.baidu.com/s/1Hidv00Yp-_iatDf-HXDEJQ
提取码:1dzb
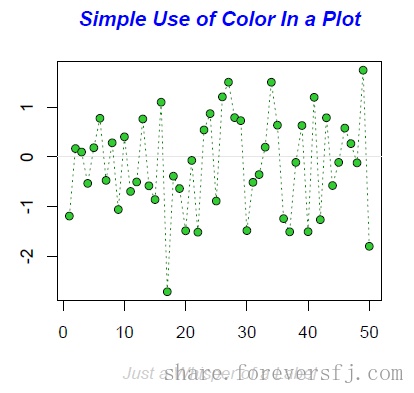
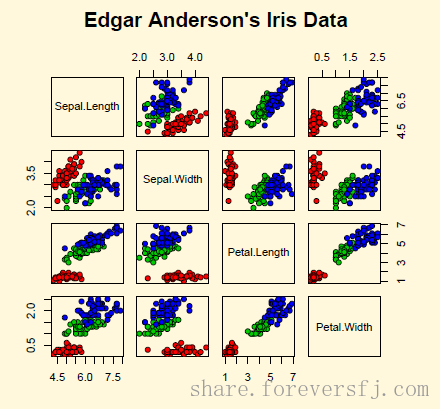
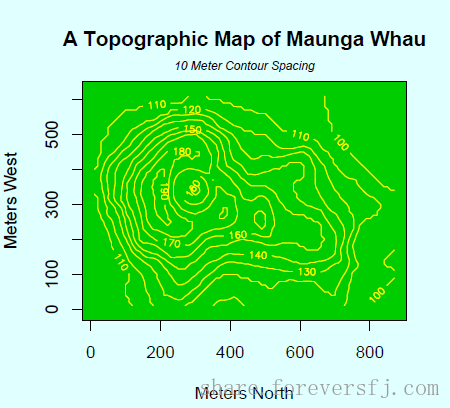
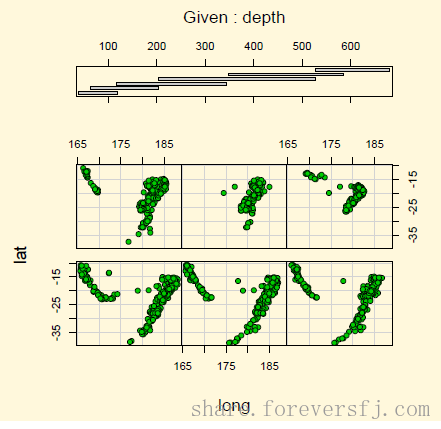
1.1. R 绘图 graphics

|
|
|
|
|
|
1.2. 计算功能
赋值:
- 简单算术运算功能,输入运算式得到结果:
1
2
3
4
5
6
7
8
9
10> 2+2
[1] 4
> exp(-2)
[1] 0.1353353
> rnorm(15)
[1] -1.475349131 -0.420342363 1.650538466 -0.350305530 -1.514609697 0.894449245
[7] -0.052745967 -1.353221501 -1.305113978 -1.574893823 -0.476416373 -0.600568454
[13] 0.001433752 -0.285181931 1.364441405- R语言中的赋值:
1
2
3
4
5
6
7> x<- -2
> x
[1] -2
> x+x
[1] -4- 不要以空格和点号作为名称的开头。
- 名称是区分大小写的。
- 最好不要以单个字母来命名。
F和T是FALSE和TRUE的标准缩写。
向量计算 Vectorized arithmetic
【例题:判断身体质量指数是否满足标准】
1 | > weight <- c(60, 72, 57, 90, 95, 72) |
- 计算均值和标准差:$SD=\sqrt{\sum(X_i-\overline{X})^2/(n-1)}$
1 | > sum(weight) |
检查bmi身体重量指数是否瞒住标准(标准bmi指数为20-25,均值为22.5)
1 | > t.test(bmi, mu = 22.5) |
2. R语言基础
2.1 函数及参数 functions and arguments
1 | x <- 10086 |
2.2 向量 vectors
- 创建简单向量
1 | # 创建简单向量 |
运行结果:
1 | > c("Huey", "Dewey", "Louie") |
- 使用函数创建向量
1 | > # 使用seq(),rep()函数创建向量 |
2.3. 矩阵与数组 matrics and arrays
- 创建矩阵
1 | > # 创建矩阵 |
- 矩阵行列名及转置
1 | > # 矩阵行列名及转置 |
- 行组合与列组合
1 | > # ⾏组合与列组合 |
2.4. 因子 factors
1 | > pain <- c(0,3,2,2,1) |
2.5. 列表 lists
1 | > # 创建数据 |
2.6. 数据框 data frames
1 | > d <- data.frame(intake.pre, intake.post) |
2.7. 索引 indexing
1 | > # 索引 |
2.8. 条件筛选 Conditional selection
1 | > # 条件筛选 |
2.9. 数据框索引
1 | > # 数据框索引 |
本文标题:R语言的基础
文章作者:foreverSFJ
发布时间:2019-06-18 14:04:46
最后更新:2019-06-18 14:04:46
原始链接:Course/ManagementStatistics/R语言基础.html
版权声明:本博客所有文章除特别声明外,均采用 CC BY-NC-ND 4.0 许可协议。转载请注明出处!
分享
